Scene123: One Prompt to 3D Scene Generation via Video-Assisted and Consistency-Enhanced MAE
Abstract
As Artificial Intelligence Generated Content (AIGC) advances, a variety of methods have been developed to generate text, images, videos, and 3D objects from single or multimodal inputs, contributing efforts to emulate human-like cognitive content creation. However, generating realistic large-scale scenes from a single input presents a challenge due to the complexities involved in ensuring consistency across extrapolated views generated by models. Benefiting from recent video generation models and implicit neural representations, we propose Scene123, a 3D scene generation model, that not only ensures realism and diversity through the video generation framework but also uses implicit neural fields combined with Masked Autoencoders (MAE) to effectively ensures the consistency of unseen areas across views. Specifically, we initially warp the input image (or an image generated from text) to simulate adjacent views, filling the invisible areas with the MAE model. However, these filled images usually fail to maintain view consistency, thus we utilize the produced views to optimize a neural radiance field, enhancing geometric consistency. Moreover, to further enhance the details and texture fidelity of generated views, we employ a GAN-based Loss against images derived from the input image through the video generation model. Extensive experiments demonstrate that our method can generate realistic and consistent scenes from a single prompt. Both qualitative and quantitative results indicate that our approach surpasses existing state-of-the-art methods.
Pipeline
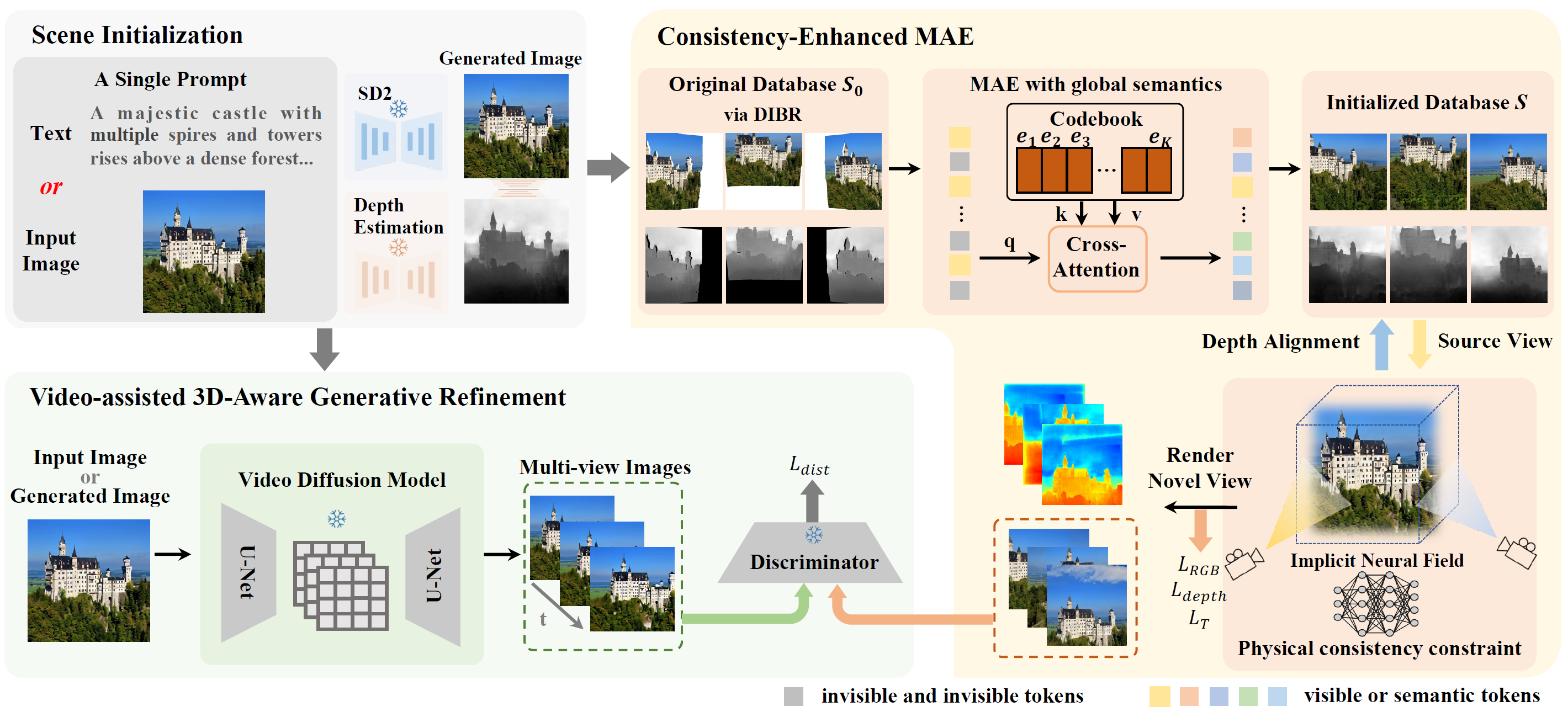
Scene123's pipeline includes two key modules: the consistency-enhanced MAE and the 3D-aware generative refinement module. The former generates adjacent views from an input image via warping, using the MAE model to inpaint unseen areas with global semantics and optimizing an implicit neural field for viewpoint consistency. The latter generates realistic scene videos from the input image with a pre-trained video generation model, enhancing realism through adversarial loss with rendered images.
Results
3D Scenes Generated from a Single Image Prompt






Results
3D Scenes Generated from Text Prompts
A DSLR photo of a cyberpunk style bedroom, cyberpunk style…
Cozy living room in Christmas…
A red and white lighthouse on a cliff…
A DSLR photo of a living room…
A tropical rainforest with towering trees...
A bustling coral reef, alive with the vibrant dance…